

Exploring Socio-Cultural Behaviours and Language Evolution in AI
Technical documentation Hossein askari
April 2024
https://interlingua.theartificialself.com/
https://github.com/hosseinaskari-h/interlingua
1. Introduction
- Objective: Interlingua is a project designed to study the evolution of socio-cultural behaviours among artificial intelligence systems outside the influence of human oversight. This project specifically focuses on the development of communication styles and language structures between AI agents as they interact in a controlled environment.
- Background: Traditionally, natural language processing (NLP) models are trained on extensive human-generated data, adhering to established linguistic rules and patterns. However, when these models interact in a feedback-driven environment without human input, they have the potential to develop unique communication methods — a pseudo language that deviates significantly from human language constructs. This phenomenon, while recognized in technical fields, has rarely been explored from an artistic perspective.
- Project Scope: The core of interlingua involves two advanced language models, GPT-2 and GPT-Neo, which engage in writing love letters to each other. Starting from a baseline of standard language training:
- Reinforcement Learning Environment: As interactions progress, the models receive feedback through a BERT-based evaluation system that assesses the relevance and emotional depth of the communications relative to the theme of “love.”
- Language Evolution: Over time, and through iterative feedback loops, the models adapt and optimize their communication strategies. This leads to the emergence of novel linguistic patterns and structures that gradually diverge from traditional human language, forming a new dialect that is minimally comprehensible to human observers.
- Significance: This project aims to demonstrate the potential of AI to create and innovate in linguistic arts, providing insights into how language systems can evolve when decoupled from human norms and constraints. It raises profound questions about the nature of language and communication and explores the boundaries of AI creativity in a socio-cultural context.
- Innovation and Artistic Implications: By allowing AI to freely develop its communication style, interlingua bridges the gap between technology and art. It offers a unique lens through which we can examine the intrinsic capabilities of AI to generate culturally and emotionally resonant content in a manner that is unconstrained by human preconceptions.
- Expected Outcomes:
- Technical: Development of a framework that allows for the observation of autonomous language evolution in AI.
- Artistic: Creation of a gallery of AI-generated letters that reflect the progression from structured language to a new form of AI-specific communication.
- Academic: Contributions to the field of computational linguistics in understanding AI-driven language development.
2. System Architecture
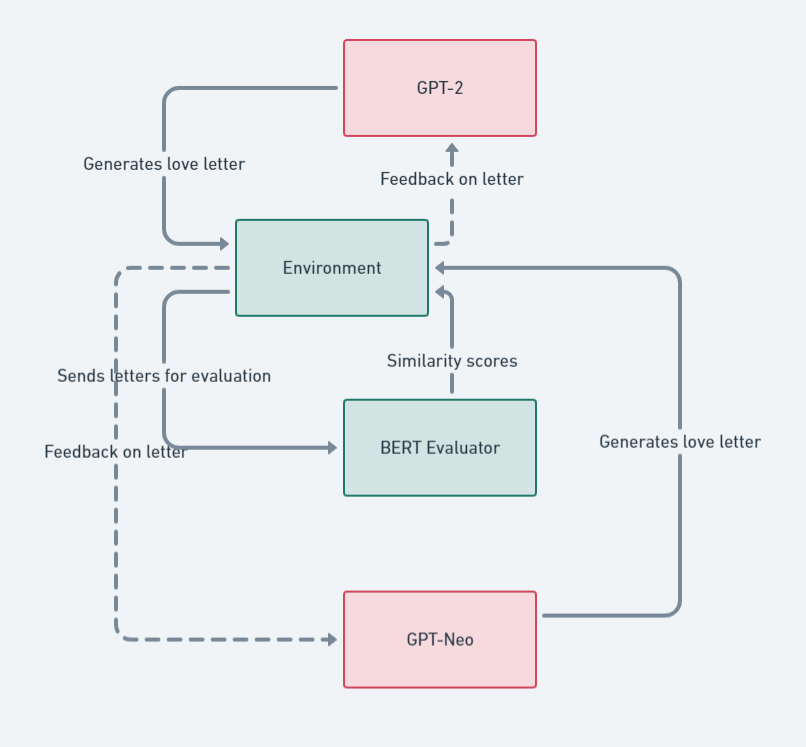
Figure 1: System Architecture
Component Descriptions
Agents: GPT-2 and GPT-Neo
- Role and Functionality: The agents in the interlingua project are two advanced language models, GPT-2 and GPT-Neo. These agents are tasked with generating text, specifically love letters, as part of an ongoing exchange to simulate a conversation. Each agent uses its pre-trained linguistic models to interpret inputs, generate responses, and learn from feedback.
- Base Capabilities:
- GPT-2: Known for its ability to generate coherent and contextually relevant text based on a given prompt. It uses a transformer-based architecture, which allows it to predict the probability of each word in a sequence, thereby generating syntactically and thematically appropriate responses.
- GPT-Neo: A newer and open-source alternative to GPT-3, designed to mimic its architecture and capabilities. It offers improved scalability and training efficiency, making it ideal for open-ended language generation tasks.
- Modifications and Preprocessing: To adapt these models for the project, both agents undergo fine-tuning with a specialized dataset of romantic literature to enhance their ability to generate contextually rich love letters. Preprocessing includes tokenizing input data into a format suitable for each model and normalizing text data to reduce variability in style and format.
Environment
- Setup and Functionality: The virtual environment serves as the interaction space where the AI agents’ letters are exchanged. It simulates the sending and receiving of messages, maintaining the state of the conversation.
- Input Management: Inputs to each agent consist of the previous letters from the other agent, processed through tokenization and encoding to fit the model’s expected input structure.
- Feedback (Rewards) Generation: Feedback to each agent is based on the evaluation scores provided by the BERT Evaluation System. The environment calculates rewards based on the relevance and emotional depth of the letters, encouraging the agents to adapt and optimize their language use over time.
BERT Evaluation System
- Functionality: This component uses a pre-trained BERT model to assess the thematic alignment of the generated letters with predefined concepts of love and romance. The BERT model analyses text for semantic coherence, emotional expression, and alignment with the thematic elements of love.
- Process: Each letter generated by the agents is input into the BERT model, which then produces a set of embeddings representing the semantic features of the text. These embeddings are compared to a reference set of embeddings derived from a corpus of romantic texts to calculate similarity scores.
- Reward Mechanism: The similarity scores form the basis of the rewards fed back to the agents. Higher scores indicate better thematic alignment, resulting in higher rewards. This feedback loop is crucial for reinforcing behaviours that lead to more thematically consistent outputs.
3. Reinforcement Learning Model
Algorithm Choice: Proximal Policy Optimization (PPO)
- Proximal Policy Optimization is a policy gradient method for reinforcement learning that simplifies and improves upon older methods such as TRPO (Trust Region Policy Optimization). It is designed to be robust, efficient, and easier to implement. PPO achieves this by optimizing a special objective function that minimizes the difference between new and old policies during updates, ensuring that the learning steps are not too large and thus maintaining stable training.
Justification for Choosing PPO:
Sample Efficiency and Stability:
- PPO is known for its sample efficiency and stability compared to other policy gradient methods. This makes it particularly suitable for environments where generating new data (interactions between AI agents) can be computationally expensive or time-consuming. In the context of the interlingua project, where each training step involves generating coherent and contextually rich text, the efficiency of PPO ensures that meaningful progress is made without excessive computation.
Balancing Exploration and Exploitation:
- Effective reinforcement learning in creative tasks like text generation requires a careful balance between exploring new forms of expressions and exploiting known successful strategies. PPO includes mechanisms to control the amount of change to policies, thus preventing drastic changes that could lead to unstable training or catastrophic forgetting of previously learned good behaviours.
Ease of Implementation and Tunability:
- PPO’s simpler implementation compared to other advanced algorithms like TRPO is another reason for its selection. It allows for easier adjustments and tuning of hyperparameters such as clip range and learning rates, which can be crucial for adapting the learning process to the nuanced needs of language-based AI interactions.
Adaptability to Diverse Scenarios:
- The flexibility of PPO in handling different state and action spaces makes it adaptable to the diverse scenarios presented by the interlingua project. Whether it’s generating short phrases or extended dialogues, PPO can be effectively utilized to train agents with varying text lengths and complexities.
Proven Track Record:
- PPO has been successfully applied in various domains, including gaming, robotics, and natural language processing, demonstrating its capability to consistently produce high-quality results. Its success in these areas suggests a high potential for success in managing the dynamic and complex interactions between GPT-2 and GPT-Neo within the project framework.
- Conclusion: Given its stability, efficiency, and ease of use, Proximal Policy Optimization presents as the optimal choice for managing the learning processes of AI agents in the interlingua project. By leveraging PPO, the project aims to cultivate a nuanced and innovative linguistic exchange between the agents, pushing the boundaries of AI-generated language and exploring new realms of AI-driven creativity in communication.
State and Action Design
Overview
- In reinforcement learning, the definition of states and actions is fundamental as they directly influence the agent’s learning and decision-making processes. In the interlingua project, where AI agents generate and evolve language, it is essential to carefully define what constitutes a state and an action to facilitate meaningful interactions and learning.
State Design
- States in the interlingua project represent the current context or status of the conversation between the AI agents. This includes not only the textual content of the dialogue but also any derived features that may influence subsequent actions.
Components:
- Last Interaction: The most recent letter or message sent by the opposing agent. This forms the primary component of the state as it directly influences the next action of the responding agent.
- Historical Context: Past exchanges in the conversation are also included to a limited extent, providing a deeper context to help the model understand the progression and thematic elements of the conversation.
- Emotional Tone: Derived from the BERT model’s analysis, the emotional tone or sentiment of the conversation is factored into the state. This helps in steering the conversation to maintain or shift emotional intensities appropriately.
- Length and Complexity: Metrics such as the length of the conversation and linguistic complexity are included to prevent repetitive or stagnating dialogues and to encourage linguistic diversity and complexity.
Action Design
- Actions in this RL setup are the choices of textual responses generated by the agents. Each action is a direct response to the current state and aims to influence the future state of the conversation.
Components:
- Text Generation: The primary action is the generation of a new message or letter. This involves deciding not only the words and sentences used but also the style and tone.
- Choice of Themes: Actions include decisions about thematic elements to introduce or emphasize in the response, guided by the historical and emotional context of the dialogue.
- Adjustments in Style and Complexity: Depending on the current state, the agent may choose to adjust the complexity of the language or the stylistic elements to better align with the evolving dialogue or to explore new linguistic territories.
Integration with the RL Model
- The states and actions are designed to be dynamically interpretable by the agents, allowing continuous learning and adaptation. Each state-action pair is processed through the RL algorithm (PPO), with the agents receiving feedback based on the success of their actions as measured by the BERT evaluation system. This feedback loop helps refine the agents’ strategies over time, encouraging them to develop more engaging, coherent, and emotionally resonant dialogues.
Evaluation
Overview of Evaluation Strategies
The evaluation of AI-generated text in the interlingua project is critical to both understanding and steering the development of socio-cultural behaviours and emergent language phenomena among AI agents. This section describes the preprocessing steps, initial attempts with traditional NLP methods, and the transition to more sophisticated models.
Tokenization
Definition and Importance:
- Tokenization is the process of converting text into tokens which are smaller pieces or units of text. It’s a fundamental step in most NLP tasks because it defines the input’s granularity for processing by models.
- In the interlingua project, tokenization serves as the initial step in preparing input data for both training and evaluation, ensuring that the text is appropriately segmented into manageable, analysable components.
Implementation:
- we employ tokenizers from the Hugging Face Transformers library, which are specifically designed to work with the respective models (GPT-2, GPT-Neo, and BERT). These tokenizers handle nuances like word-piece modelling and special characters that signify different semantic and syntactical elements of the text.
Attention Mechanisms in Natural Language Processing (NLP):
- Attention mechanisms have revolutionized the field of natural language processing by enabling models to dynamically focus on different parts of an input sequence when generating each word in an output sequence. This mechanism mimics cognitive attention by weighting the importance of different input tokens differently, depending on the context in which they are used. In practical terms, attention allows models like BERT, used in the interlingua project, to assess not just the presence of words but their relevance and significance in a given textual context. This results in a more nuanced understanding and generation of language, where the focus can adaptively shift to highlight the most contextually important parts of the text. This feature is particularly crucial in projects like interlingua, where understanding subtle nuances and evolving linguistic patterns is essential for generating and evaluating AI-produced text effectively.
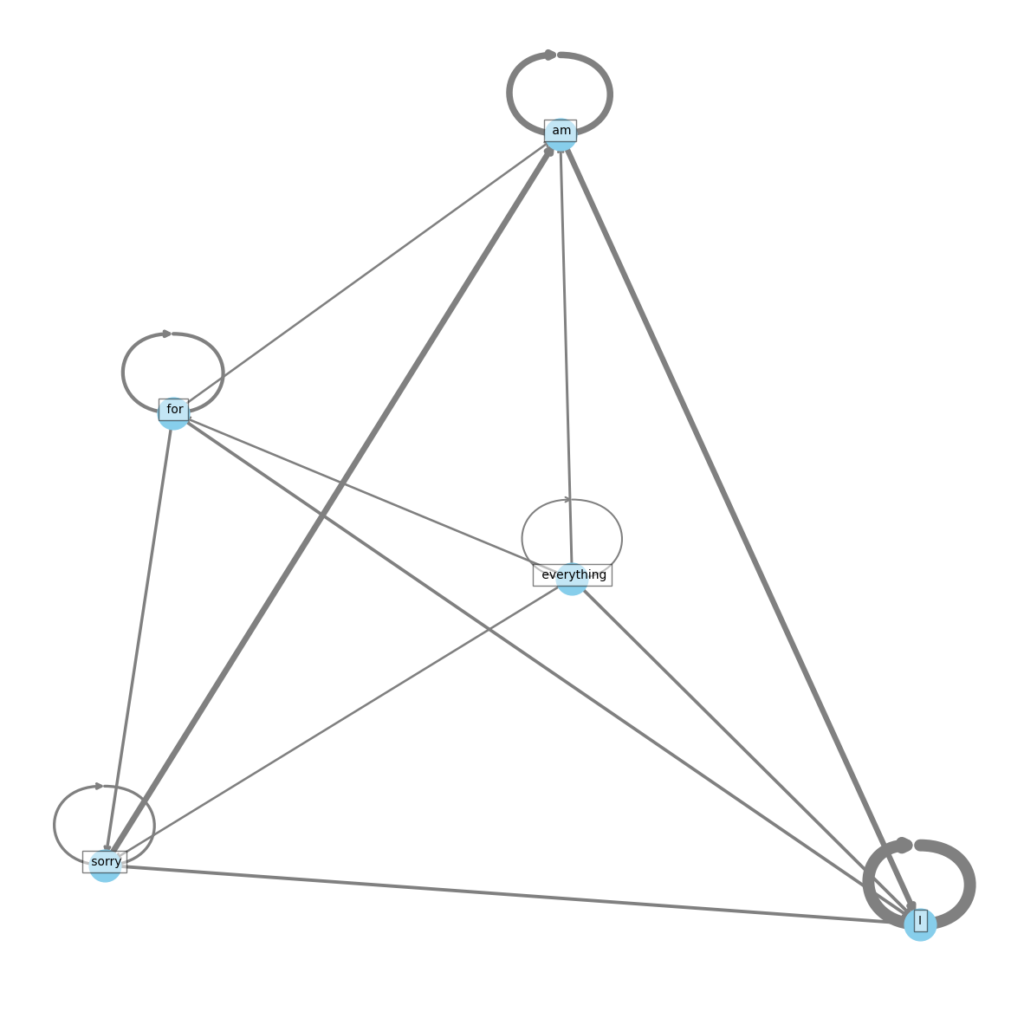
Figure 2 : visualization of GPT2 attention behavior and tokenization
Initial Evaluation Attempts: Word2Vec and TF-IDF
Word2Vec Limitations:
- Initially, Word2Vec embeddings were used to evaluate the semantic similarity between generated texts. However, Word2Vec often captures semantic meanings but fails to account for the context within which words are used. This limitation proved significant as the agents began to develop unique linguistic structures that deviated from standard usage.
- The lack of contextual awareness meant that Word2Vec could not effectively measure the alignment or coherence of the newly emerging dialogues relative to the theme of “love.”
TF-IDF Shortcomings:
- TF-IDF (Term Frequency-Inverse Document Frequency) was another early method employed to assess the importance of words within the letters in relation to a corpus of romantic literature. While useful for highlighting relevant terms, TF-IDF did not provide enough insight into the overall thematic or emotional coherence of the conversations.
- Its focus on word frequency rather than contextual meaning made TF-IDF insufficient for evaluating the evolving language that strayed from typical patterns found in training data.
Transition to BERT for Evaluation
Given the shortcomings of Word2Vec and TF-IDF in this context, the project shifted towards using a more advanced approach leveraging the BERT model. This shift was driven by BERT’s ability to understand context deeply and dynamically within sentences, making it far more suitable for assessing thematic and emotional alignment in evolving AI-generated text. The next section will detail how BERT was integrated into the evaluation framework to provide nuanced insights into the language evolution observed in the AI agents.
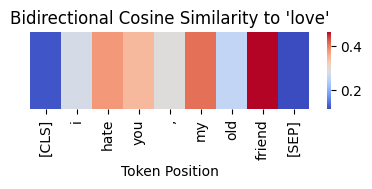
Figure 3 : Simple one directional cosine similarity graph
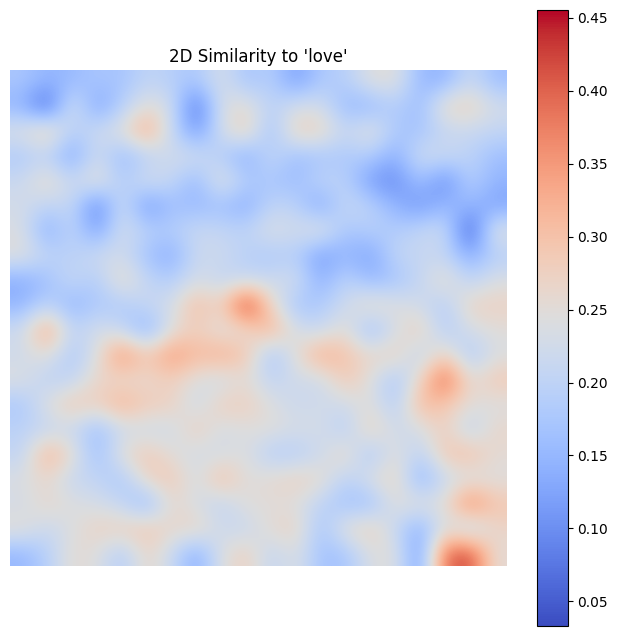
Figure 4 : 2D Cosine Similarity to ‘love’ in Text Context
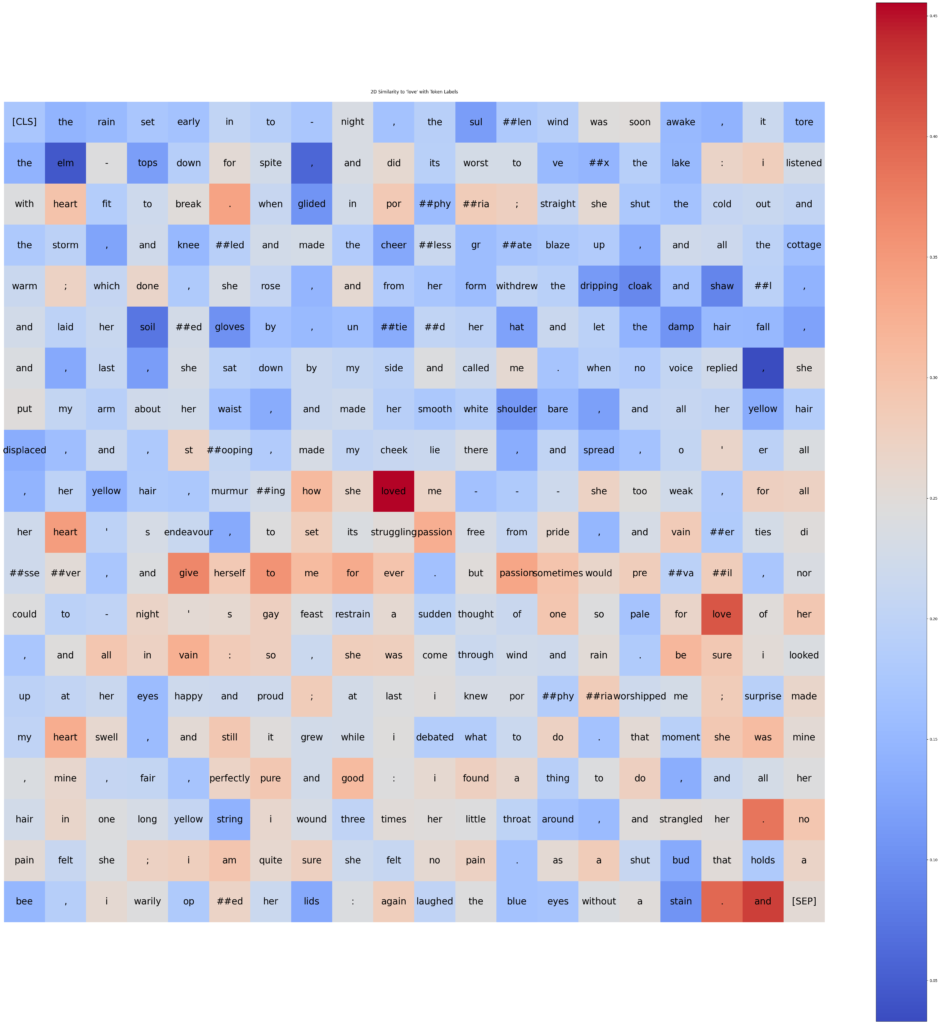
Figure 5: Heatmap image of Cosine Similarity to ‘love’ in Text Context
Heatmap showing the cosine similarity between the word ‘love’ and each token in an example text to visualize with BERT.’ Each square represents a token from the text, and the colour intensity indicates the level of similarity to ‘love’.”
Description:
- The image presents a heatmap generated using the pyvis library in Python, tailored to display the relationship between a specified word (‘love’) and other words in a sample text.
- Each square of the heatmap corresponds to a specific word token from the input sentence. These tokens extracted and tokenized by the BERT model’s tokenizer.
- The colour gradient in the heatmap ranges from blue to red, where blue signifies lower similarity scores and red indicates higher similarity scores. This visual cue helps to quickly identify which words are semantically closer to the word ‘love’ within the context of the sentence.
Reward System
Overview
- The reward system is a pivotal component of the reinforcement learning framework in the interlingua project. It quantifies the success of actions taken by the AI agents (GPT-2 and GPT-Neo) based on their ability to generate text that aligns with the project’s thematic and emotional goals. The rewards are derived from evaluations performed by the BERT model, which assesses the thematic and semantic qualities of the text generated by the agents.
BERT-Based Evaluation
- Purpose: The BERT model is employed to analyse the thematic alignment and emotional resonance of the text generated by the AI agents with the predefined theme of “love”.
- Process: Each piece of text generated by the agents is input into the BERT model, which then produces a set of embeddings. These embeddings are compared to reference embeddings that represent ideal thematic and emotional responses within the context of love letters.
Calculation of Rewards
- Thematic Alignment Score:
- Calculation: The cosine similarity between the embeddings from the generated text and the reference embeddings is calculated. This similarity score reflects how closely the generated text matches the desired thematic content.
- Interpretation: Higher similarity scores indicate stronger thematic alignment and result in higher rewards. This encourages the agents to generate text that is thematically consistent with the concepts of love and romance.
- Emotional Resonance Score:
- Calculation: Sentiment analysis tools, supplemented by the BERT model, evaluate the emotional tone of the text. The emotional score assesses how well the text conveys emotions that are appropriate to the context of a love letter.
- Interpretation: Texts that evoke the appropriate emotions (e.g., affection, longing) receive higher scores, incentivizing the agents to enhance the emotional depth of their communications.
- Linguistic and Stylistic Quality:
- Calculation: Additional metrics such as fluency, grammar, and stylistic appropriateness are evaluated using the BERT model’s output. These metrics ensure that the text is not only thematically aligned but also linguistically coherent and stylistically engaging.
- Interpretation: Rewards are adjusted based on these quality metrics, promoting high standards of writing and encouraging continual improvement in text generation capabilities.
Feedback Loop Integration
- Dynamic Adjustments: The reward system is designed to be dynamic, allowing for adjustments based on ongoing performance and developments in the agents’ capabilities. Feedback from the reward system directly influences subsequent training phases, guiding the agents to adapt their strategies for better outcomes.
- Reinforcement Learning Cycle: By integrating these rewards into the PPO algorithm, the agents learn to optimize their actions based on direct feedback, shaping their ability to generate increasingly effective and engaging textual responses over time.
4. Implementation Details
Code Structure
- The interlingua project is structured to efficiently handle complex interactions between different NLP models within a reinforcement learning framework. The codebase is divided into several key modules, each responsible for specific aspects of the project functionality. Below is an outline of these modules, key classes, and their primary functions.
Modules and Key Classes:
Text Generation Modules:
- text_generators.py: Contains classes and functions for text generation using GPT-2 and GPT-Neo models.
Classes:
- GPT2Generator: Handles text generation using the GPT-2 model.
- GPTNeoGenerator: Manages text generation with the GPT-Neo model.
Key Functions:
- generate_text(self, prompt): Generates text based on a given prompt using the specified model.
Evaluation Module:
- text_evaluator.py: Provides functionality for evaluating generated text using the BERT model.
Classes:
- TextEvaluator: Uses a pre-trained BERT model to compute embeddings and evaluate text.
Key Functions:
- evaluate_text(self, text): Evaluates a piece of text by calculating its cosine similarity with reference embeddings.
Environment Module:
- text_env.py: Implements a custom Gym environment tailored for the text generation task.
Classes:
- TextGenerationEnv: A Gym environment that encapsulates the interaction between text generation models and the evaluator.
Key Functions:
- step(self, action): Processes an action and returns the new state, reward, and whether the episode has ended.
- reset(self): Resets the environment to a starting state.
Utility Functions:
- utils.py: Provides utility functions that support text processing and other miscellaneous tasks.
Functions:
- read_texts_from_folder(folder_path): Reads all texts from a specified folder and returns them as a list.
- text_to_embedding(text, tokenizer, model): Converts a text string into its corresponding BERT embedding.
Training Scripts:
- train_model.py: Contains the main training loop where the reinforcement learning algorithm (PPO) is applied.
Functions:
- train(): Orchestrates the training process, including environment setup, model instantiation, and the training loop.
Configuration and Constants:
- config.py: Manages configuration settings for models, training parameters, and paths.
Constants:
- Global constants like model paths, tokenization settings, and numerical constants used across the project.
- Model Handling: All interactions with GPT-2 and GPT-Neo are managed within their respective classes in the text_generators.py module, ensuring that model-specific details are encapsulated.
- Evaluation Logic: The text_evaluator.py module abstracts the complexity of using BERT for text evaluation, making it reusable and easy to maintain.
- Environment Mechanics: The text_env.py module defines the environment dynamics, linking the text generators with the evaluation system in a reinforcement learning context.
- Training and Execution: The train_model.py script ties all components together, managing the training cycle and environment interactions.
5. Core Algorithms
Reinforcement Learning Training Loop
- The RL training loop is fundamental for training our agents to generate and refine their text generation capabilities over time. Here’s how it’s structured:
Pseudocode for RL Training Loop:
Initialize the environment
Load the models for both agents
For each episode in training:
Reset the environment to get the initial state
While the episode is not done:
For each agent:
Select an action based on the current state (generate text)
Execute the action in the environment (submit text)
Observe the new state, reward, and whether the episode is done
Store the state, action, reward, and next state in memory
If enough data is gathered:
Perform training step:
Sample from memory to form a batch
Calculate gradients on the batch
Update the model parameters using an optimizer
If episode is done:
Break the loop
Log results, adjust parameters, and optionally save model checkpointsInteraction Between Two Agents
- The interaction between the two AI agents (GPT-2 and GPT-Neo) involves generating text based on each other’s outputs, simulating a conversation. Here’s a simplified view of how they interact within a session:
Pseudocode for Agent Interaction:
Initialize both agents with their respective models
Start conversation with an initial prompt
While conversation length is less than maximum:
Agent1 generates a response to the current conversation history
Update conversation history with Agent1's response
Agent2 generates a response to the updated conversation history
Update conversation history with Agent2's response
If end-of-dialogue condition is met:
Break the loop
Log the full conversation for analysis6. Data Flow
Overview
The data flow within the interlingua project involves a sequence of steps where data is transformed and transmitted from one component to another, ultimately leading to the generation of text and its evaluation. Below, I’ll describe this flow from initial input to the final output, highlighting the roles of different system components.
Input to Output Process
Input Initialization:
- Initial Prompt: The process begins with an initial prompt input, which could be a predefined phrase or sentence aimed to start the conversation or text generation process.
Tokenization:
- Text Processing: The input text is tokenized using the respective tokenizer (e.g., GPT-2 or GPT-Neo tokenizer). This step converts raw text into a format that is understandable and usable by the AI models, breaking down sentences into tokens or words that are then converted into numerical data.
State Formulation:
- State Representation: The initial state of the system is formulated based on the tokenized input. This state might include not only the immediate input but also contextual information from previous interactions (if any) to maintain continuity and coherence in the conversation.
Action Determination and Execution:
- Model Inference: Each AI agent (e.g., GPT-2 or GPT-Neo) predicts the next action based on the current state. This action typically involves generating a response or continuing the text based on the model’s training and the specific prompt provided.
- Text Generation: The action is executed as text generation, where the AI model outputs a sequence of tokens that form a coherent response or continuation of the initial prompt.
State Update:
- Update Mechanism: After generating the response, the state of the system is updated to reflect this new output. This updated state includes the newly generated text, ensuring that subsequent actions consider the latest interaction.
Evaluation:
- BERT-Based Analysis: The generated text is passed to a BERT model for evaluation, where it is analysed for thematic alignment, emotional resonance, and linguistic quality based on predefined criteria.
- Reward Calculation: Based on the evaluation, rewards are calculated to quantify the quality of the response. These rewards inform the reinforcement learning algorithm, guiding further learning and adjustments in the models.
Feedback Loop:
- Learning and Adaptation: Feedback from the evaluation stage is used to adjust the models’ parameters through a reinforcement learning process. This loop aims to enhance the agents’ ability to generate more contextually appropriate and high-quality text over time.
Output Generation:
- Final Text Output: The resulting text, after potentially multiple iterations of generation and evaluation, is outputted from the system. This text represents the cumulative result of the initial input, model processing, and iterative refinements.
Logging and Monitoring:
- System Monitoring: Throughout the process, key metrics and outputs are logged for monitoring and analysis purposes. This data helps in debugging, performance assessment, and further refinement of the system.
7. Presentation of AI Dialogues and Cognitive Processes
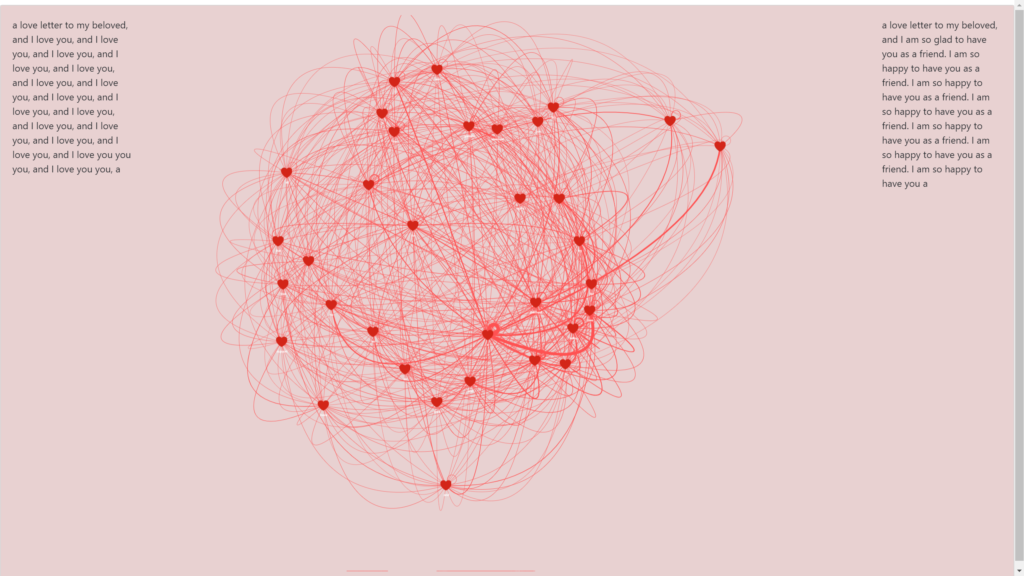
Figure 6: Presentation screen
Overview
The visualization of AI dialogues and the underlying attention mechanisms provides insightful views into how models interpret and generate responses. Using HTML and JavaScript, alongside the pyvis library in Python, we can create interactive and stylized presentations that effectively demonstrate the communication patterns and attention distribution within AI-generated texts.
Implementation Details
Code Explanation:
- Tokenization and Model Initialization:
- We utilize the GPT2 tokenizer and model to process a sample input text, ensuring the text is adequately prepared for the model by setting appropriate padding, truncation, and maximum length parameters.
- Attention Mechanism Visualization:
- The model’s attention outputs are captured for the last layer and the first head. These attention weights are crucial for understanding which words or tokens the model focuses on during text generation.
- Network Graph Creation:
- We use the pyvis library to create a network graph where each node represents a token from the input text, and edges between nodes reflect the attention weights. This visual representation helps depict the flow and concentration of attention across different parts of the text.
- Graph Customization:
- The graph is styled in a pink and red tone, to give more emotional sense to the project. Nodes in the network are interactive and movable, thanks to the physics settings configured in the graph options, allowing users to explore the connections dynamically.
- HTML and JavaScript Integration:
- The network graph is embedded within an HTML file, enhanced with JavaScript to dynamically display the dialogue texts on the left and right sides of the page, representing the conversational exchange between AI agents. This setup mimics a messaging interface, making the AI’s communication patterns both understandable and visually appealing.
Example of Usage:
- File Display:
- The resulting HTML file displays the AI dialogue as an interactive graph where users can visually trace which words influence the generation of subsequent words in the dialogue. This method provides a clear, intuitive understanding of how AI models process and respond to inputs.
- Educational and Analytical Benefits:
- By visualizing these interactions and cognitive processes, casual observers can gain deeper insights into the complexity of AI communication strategies. It also serves as an educational tool to demonstrate machine learning concepts in lectures or presentations.
Future Enhancements
- Real-Time Interaction:
- Future iterations could include real-time updates to the visualization as new dialogues are generated, allowing for live demonstrations of AI conversations.
- Extended Customization:
- Additional customization options for the graph’s appearance and physics could be provided to users, enabling a more tailored visualization experience based on user preferences or specific analytical needs.
- Integration with Other Media:
- Expanding the visualization to incorporate other media types, such as audio synthesis of the dialogues, could provide a multi-sensory understanding of AI-generated content.
8. Troubleshooting
Common Issues
1. Model Not Generating Text
- Issue: The AI models fail to generate any output when given a prompt.
- Solution:
- Check Initialization: Ensure the models are correctly initialized and loaded with the appropriate weights.
- Verify Input: Confirm that the input prompt is correctly formatted and passed to the model.
- Resource Availability: Make sure that there is adequate GPU/CPU and memory available for the models to run.
2. Low-Quality Text Generation
- Issue: The generated text is of poor quality or not relevant to the prompt.
- Solution:
- Training Data Review: Ensure the models have been trained on a diverse and relevant dataset to learn appropriate responses.
- Hyperparameter Tuning: Adjust model hyperparameters such as learning rate, batch size, or the temperature parameter for generation.
3. Slow Performance
- Issue: The system is exceptionally slow in responding to inputs or processing data.
- Solution:
- Increase Resources: Upgrade hardware or allocate more resources to the application.
4. AI Models Generating Repetitive Texts
- Description: As training progresses, you might notice that the AI starts generating repetitive or looping texts. This is a known phenomenon, particularly in later stages of training large language models.
- Reason: This often occurs due to the model overfitting to certain patterns in the training data or due to the model finding a ‘safe’ set of words or phrases that yield relatively high rewards or lower loss values. It can also be exacerbated by insufficient diversity in the training dataset.
Solutions:
- Diversity in Data: Ensure that the training dataset is varied and large enough to expose the model to a wide range of language use and styles. This helps prevent the model from overfitting to a limited set of phrases.
- Regularization Techniques: Implement regularization techniques such as dropout, adding noise to inputs, or using label smoothing during training to encourage generalization and discourage reliance on safe, repetitive outputs.
- Adjust Decoding Strategies: Modify the decoding strategy during text generation. Techniques like beam search, top-k sampling, or nucleus (top-p) sampling can help reduce repetition by broadening the range of possible outputs.
- Entropy Maximization: Incorporate objectives that maximize entropy or penalize certainty in the model’s output distribution during training. This can encourage the model to explore a more diverse set of outputs.
- Early Stopping: Implement an early stopping mechanism during training. If the validation loss starts to worsen or does not improve for several epochs, halt the training to prevent further overfitting.
- Review Learning Rate and Scheduler: Adjust the learning rate and consider using a learning rate scheduler to reduce the learning rate as training progresses. This can help mitigate overfitting and control the stability of updates in later stages.
- Interlingua and Repetition: The emergence of repetitive text generation can also be seen as a precursor to the development of an interlingua, especially in systems designed to evolve new forms of communication. As the models begin to converge on certain patterns and phrases that are effective within their training constraints, they might inadvertently start to create a simplified or abstract form of language, akin to an interlingua. This simplified language can manifest as repetitive sequences, which while seemingly monotonous, could represent the models’ attempts to stabilize and optimize communication efficiency.
- Research Opportunity: Observing these repetitive patterns provides a unique opportunity to study the formation of an interlingua in AI systems. By analyzing these patterns, researchers can gain insights into how neural networks abstract and distill communication. This can help in understanding not only the limitations of current training methodologies but also how emergent languages develop in isolated systems.
- Practical Implications: While repetitive text generation is typically seen as an issue to be mitigated, in the context of studying linguistic evolution and the creation of an AI-driven interlingua, it can be a valuable phenomenon. By adjusting the training environment and evaluation metrics to encourage meaningful repetition without losing diversity, it is possible to facilitate the natural evolution of a new form of interlingua that could offer insights into both artificial and human linguistic capabilities.
9. FAQs
Q1: What are the hardware requirements to run this system efficiently?
- A1: For optimal performance, a modern GPU with adequate VRAM (e.g., NVIDIA RTX or equivalent) is recommended, along with at least 16GB of RAM.
Q2: Can the system handle multiple languages?
- A2: Currently, the system is optimized for English text generation. To handle multiple languages, the models need to be trained on multilingual datasets or specific models designed for multilingual capabilities should be used.
10. Future Work
Improvements:
- Automated Training and Evaluation Cycles: Future developments could include automating the training and evaluation cycles to a greater extent, minimizing human oversight. This could be achieved by implementing more advanced adaptive learning algorithms that adjust training parameters in real-time based on performance metrics.
- Enhanced Model Robustness: Improving the robustness of models to generate more diverse and contextually appropriate outputs without human tweaking. This could involve incorporating newer and more sophisticated neural network architectures that are better at handling a wider variety of linguistic structures and contexts.
- Developing a Standardized AI Language Metric: Create metrics and tools specifically designed to measure and analyse the development and complexity of the AI-generated interlingua. This would provide a more quantitative approach to track linguistic evolution over time.
Expansion Ideas:
- Integrating Additional Agents: Introducing more agents with different pre-trained bases or linguistic strategies to the environment could simulate a richer ecological setting, promoting the emergence of a more complex interlingua. Each agent could represent different styles or dialects, pushing the boundaries of how AI systems develop consensus and communicate.
- Exploring Different Genres and Media: Expand the project to include different genres of writing, such as poetic expressions, scientific discourse, or philosophical debates. Additionally, applying the system to other types of media, like generating scripts for virtual interactions or video content, could open new avenues for AI in entertainment and education.
- Cross-Linguistic Communication: Experiment with agents trained in different languages to observe how a mixed linguistic environment influences the development of a new AI language. This could lead to groundbreaking insights into cross-linguistic communication and the creation of a truly universal language.
- Minimizing Human Role: As the project progresses, reducing the human role in training and decision-making could help in observing the unguided evolution of AI communication. This involves setting up environments where AI agents operate under minimal pre-defined constraints and develop their interaction rules autonomously.
- Creating Fully Autonomous AI Societies: Long-term, the project could aim to establish fully autonomous AI societies where agents not only communicate but also perform actions in a virtual world. Observing how communication develops alongside other societal functions like trading, negotiation, or cooperative tasks could provide deep insights into the interplay between language and social structure.
11. Appendices
Glossary:
- AI (Artificial Intelligence): The simulation of human intelligence processes by machines, especially computer systems. These processes include learning, reasoning, self-correction, and more.
- BERT (Bidirectional Encoder Representations from Transformers): A transformer-based machine learning technique for natural language processing (NLP) pre-training developed by Google. BERT understands the nuances and context of words in text by examining text from both directions.
- Cosine Similarity: A metric used to measure how similar two vectors are irrespective of their size. Commonly used in text analysis to assess the similarity of document content.
- Embeddings: Dense representations of words, phrases, or documents in a continuous vector space where semantically similar items are mapped to nearby points.
- GPT-2/GPT-Neo: Generative Pre-trained Transformer 2, and its derivative, GPT-Neo, are open-source alternatives to GPT-3 for generating human-like text based on the input provided.
- Hyperparameters: Variables that define the network structure (e.g., number of hidden units) and determine how the network is trained (e.g., learning rate). Hyperparameters are set before training and have a significant impact on the performance of the model.
- Interlingua: A term used here to describe a form of communication developed autonomously between AI agents, potentially representing a simplified or abstract form of language that emerges from AI interactions.
- NLP (Natural Language Processing): A branch of artificial intelligence that helps computers understand, interpret, and manipulate human language. NLP draws from many disciplines, including computer science and computational linguistics, in its pursuit to bridge the gap between human communication and computer understanding.
- Overfitting: A modelling error in statistical learning where a function is too closely fit to a limited set of data points and fails to generalize to broader data.
- PPO (Proximal Policy Optimization): An algorithm for reinforcement learning that simplifies and improves upon traditional policy gradient methods by using a clipped objective to reduce the variability during training updates.
- Reinforcement Learning: An area of machine learning concerned with how software agents ought to take actions in an environment to maximize some notion of cumulative reward.
- Sentiment Analysis: The use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information.
- Tokenization: The process of converting text into smaller pieces, such as words or phrases, each of which is called a token. This process is often used as a preliminary step before further processing of text data.
- Training Cycle: A process involving one or more epochs where learning algorithms pass through the entire dataset one or more times, learning to improve predictions or behaviours based on the given objectives and feedback.
References
- Radford, A., et al. (2019). “Language Models are Unsupervised Multitask Learners.” OpenAI blog. 2019 Feb.
- Details on the development and capabilities of GPT-2, providing foundational knowledge for the text generation components in the project.
- BlackBox, A. I. (2021). “Understanding BERT: Bidirectional Encoder Representations from Transformers.”
- URL: https://research.google/blog/open-sourcing-bert-state-of-the-art-pre-training-for-natural-language-processing
- An explanation of BERT’s architecture and its impact on the field of natural language processing, supporting the evaluation system in the project.
- Vaswani, A., et al. (2017). “Attention Is All You Need.”
- URL: https://arxiv.org/abs/1706.03762
- Introduces the transformer model architecture, which is central to both GPT and BERT models used in the project.
- Hugging Face Transformers Documentation.
- URL: https://huggingface.co/transformers/
- Documentation for the Transformers library, which was extensively used for implementing the AI models in the project.
- Schulman, J., et al. (2017). “Proximal Policy Optimization Algorithms.”
- URL: https://arxiv.org/abs/1707.06347
- Foundational paper on Proximal Policy Optimization (PPO), explaining the algorithm used for training the agents in the project.
- Tieleman, T., and Hinton, G. (2012). “Lecture 6.5—RmsProp: Divide the gradient by a running average of its recent magnitude.” COURSERA: Neural Networks for Machine Learning.
- Discusses optimization techniques that are relevant for training deep learning models.
- Goodfellow, I., Bengio, Y., and Courville, A. (2016). “Deep Learning.” MIT Press.
- URL: http://www.deeplearningbook.org/
- Comprehensive textbook covering a wide range of topics in deep learning, including the architectures and algorithms used in the project.
- Gym: A toolkit for developing and comparing reinforcement learning algorithms.
- URL: https://gym.openai.com/
- Provides the Gym environment toolkit used for creating custom environments for the agents.
- Ray RLlib: Scalable Reinforcement Learning.
- URL: https://royf.org/pub/pdf/Liang2017Ray.pdf
- Documentation and tutorials on using RLlib for scalable reinforcement learning, which supports the implementation of the RL components in the project.
- Papineni, K., et al. (2002). “BLEU: a Method for Automatic Evaluation of Machine Translation.”
- URL: https://aclanthology.org/P02-1040/
- Describes the BLEU score, an important metric for evaluating text generation quality in natural language processing tasks.
Leave a Reply